Near the start of the COVID-19 pandemic, I was inspired to see what I could do to model its spread. Thanks to various open-source data sources, I was able to throw together a simple epidemiological model in about two days. I spent a lot of time refining it and adding bells and whistles. In the end, the diverse responses of the 200+ countries around the world made it infeasible to tune the model, at least with the resources available to me. There was no longer a viable general approach to be taken, and I abandoned the project. But, the results are still interesting, and the approach is novel. A long time ago I read a great book, The Ghost Map, which described the history of Cholera. It's a great read and definitely sparked my interest in epidemiology.
At the start of the project, I realized that population density was probably an important factor in the spread of disease. I searched for a map of population density and found this one of Europe.
It's great data, but generally lacks some important features, such as a simple projection grid and country regions. I did run the initial simulations with this data, but eventually switched to global data provided by the US government.
The dataset I ended up using was a 2020 population extrapolation from SEDAC. This data is provided in a range of really convenient formats that can be read directly into matrices by Python.
Although they provide higher-resolution data, I chose the 5 km grid because although my machine is pretty good (i7-7700k @ 4.8 GHz, 48 GB RAM @ 3200 GHz), even this dataset is very very large. The data is 8640x4320 pixels, so with each pixel stored as a double, that's about 300 MB. More on this later.
The GEOTiff format can be directly read into a NumPy-compatible array using CV2 as follows:
P = cv2.imread('./PopData/gpw_v4_population_count_rev11_2020_' + data_series + '.tif', cv2.IMREAD_UNCHANGED)
I later added the ability to filter results by country, which is important for regional model tuning, and also because people are more interested in where they live. The SEDAC dataset also includes a map of countries (National Identifier Grid, v4.11 (2010)) again as GEOTiff, with values that can be cross-referenced using gpw-v4-country-level-summary-rev11.xlsx in the included documentation. That took me a while to figure out.
Unfortunately most of the population data is region-based rather than pixel-based. This means that, for example, the virus spreads through the Saharan desert quite effectively. This is not realistic.
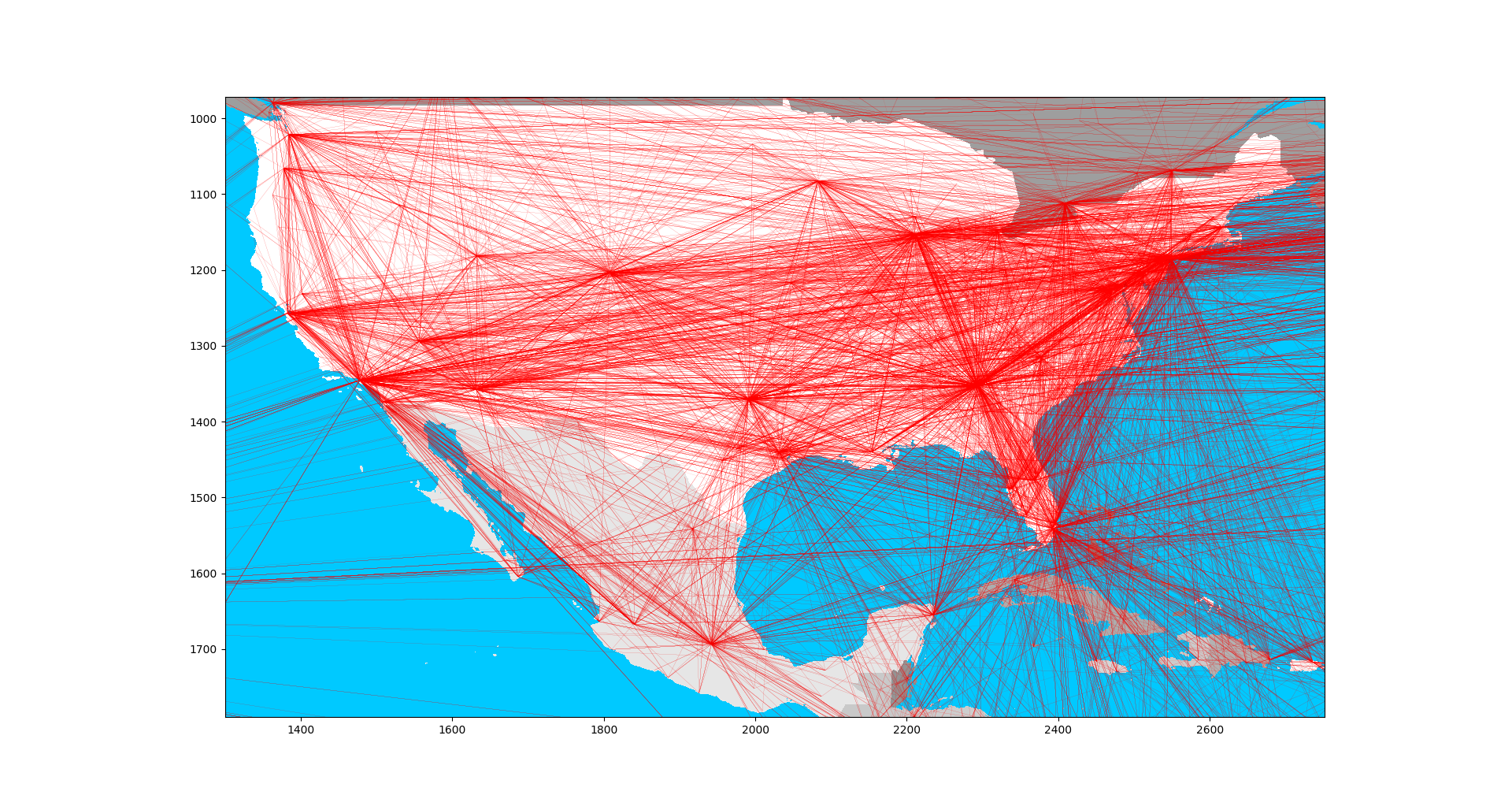
Originally, I was simulating the international spread by randomly sprinkling infection around the globe at each step, in proportion to the total number of daily flights. This was really crude and the results were just dumb. I knew I had to build the flight network into the simulation.
This was not trivial. I found a dataset that defined all airport locations, and all route pairs, and distilled it into a newtwork data structure. But how to drive infectious traffic through this network? The route dataset has airplane models. The FAA has a model seating capacity dataset. By combining these two datasets, the total capacity of each route could be estimated. Some routes had multiple aircraft types. I took the average seating capacity of all types for each route, and multiplied it by a load factor (0.8).
To my surprise, this more focused approach gave about the same number of daily passengers of 10.5 million as a previous estimate I'd made when using random sprinkling.
Infections are sourced from within a 100 km radius of each airport, and proportionally transmitted to the most populous cells surrounding each destination airport.
There were a few errors in the datasets, and an airport called FUN made my code crash because it was on the longitude where the map ends/wraps.
This model has two methods of transmission. The previously mentioned flight network, and local spreading. Local spreading is achieved by a simple Game of Life style diffusion mechanism. The actual implementation is a normal distribution convolution kernel. The entire infected matrix I is convoluted using this matrix, which leads to a spreading effect. This effect can be tuned by modifying the normal distribution parameters. The sum (area integral) of the convolution kernel is loosely related to the reproduction number.
Here's the 6x6 kernel I used. The sum is the main parameter used to tune the model to observed data.
Here's an early attempt at building a good kernel that was thwarted by an integer division error. I thought it was pretty. Large kernels are possible and don't slow down the convolution operation as much as you'd think.
Some available fast convolution filters have problems. I ended up just using the standard convolution available in NumPy. It is unfortunately quite slow and limiting, because it doesn't operate on sparse matrices.
The convolution approach generally leads to spreading patterns that look like this plot of infections in BeNeLux, when healing isn't considered.
Initially, I was only considering infections, not deaths. To model deaths you need to know the demographic data. SEDAC has that too. I load 17 global matrices, each containing the population within an age band. The mortatlity rates for each age band have been estimated and can be used to calculate a crude demographics-based global maximum for deaths assuming that everyone gets infected.
You also need to include healing effects, or else you overestimate the number of infections. Unfortunately, tracking the infection time history means you have to store many copies of the infections matrix (one for each timestep). I used a ring buffer to store only the last N days with of data, where N is the healing time.
Shown at right is a global map of people older than 70.
The overall approach is an SIR model. R is actually H (healed) and D (deaths), so it's a SIHD model. Those four matrices are the basis of the transient simulation.
So let's look at some plots. Below is New Zealand with a spread rate of 1.4, and an infectious time of 7 days. No preventative measures are taken. It takes a while for the virus to get to NZ through the flight network. The total number of deaths is 11780, but would be 37800 if everyone were infected. People may not be infected because it dies out before reaching them, due to geological separation and the assumed healing time of 7 days.
Future work might include adding the open street map (OSM) road network (and maybe pivoting to traffic simulations).